In NetApp Storage system, RAID feature will provide the fault tolerance in-case of any disk failures. But what will happen if the controller(node) itself fails ? NetApp ships the controllers as HA pairs (Two controllers in one chassis ). If one node fails , automatically other controller will take over the storage. Enabling storage failover (SFO) is done within pairs, regardless of how many nodes are in the cluster. For SFO (storage failover), the HA pairs must be of the same model. The cluster itself can contain a mixture of models, but each HA pair must be homogeneous. The version of the Data ONTAP operating system must be the same on both nodes of the HA pair, except for the short period of time during which the pair is upgraded. Two HA interconnect cables are required to connect the NVRAM cards (except for FAS and V-Series 32×0 models with single-enclosure HA). The storage failover(SFO) can be enabled on either node in the pair. Storage Failover(SFO) can be initiated from any node in the cluster.
Cluster high availability (HA) is activated automatically when you enable storage failover on clusters that consist of two nodes, and you should be aware that automatic giveback is enabled by default. On clusters that consist of more than two nodes, automatic giveback is disabled by default, and cluster HA is disabled automatically.
Let’s have closer look at HA Pairs:
HA pair controllers are connected to each other through an HA interconnect. This allows one node to serve data that
resides on the disks of its failed partner node. Each node continually monitors its partner, mirroring the data for each other’s nonvolatile memory (NVRAM or NVMEM). The interconnect is internal and requires no external cabling if both controllers are in the same chassis.
resides on the disks of its failed partner node. Each node continually monitors its partner, mirroring the data for each other’s nonvolatile memory (NVRAM or NVMEM). The interconnect is internal and requires no external cabling if both controllers are in the same chassis.
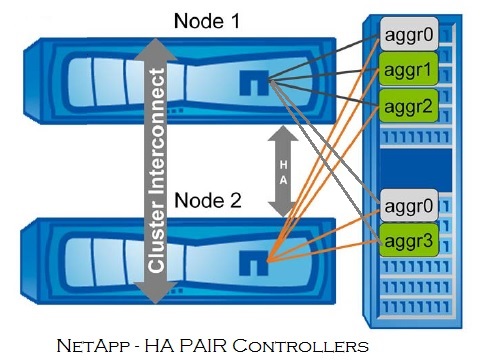
HA pairs are components of the cluster, and both nodes in the HA pair are connected to other nodes in the cluster
through the data and cluster networks. But only the nodes in the HA pair can take over each other’s storage. Non-HA nodes are not supported in a cluster that contains two or more nodes. Although single-node clusters are supported, joining two single-node clusters to create one cluster is not supported, unless you wipe clean one of the single-node clusters and join it to the other to create a two-node cluster that consists of an HA pair.
through the data and cluster networks. But only the nodes in the HA pair can take over each other’s storage. Non-HA nodes are not supported in a cluster that contains two or more nodes. Although single-node clusters are supported, joining two single-node clusters to create one cluster is not supported, unless you wipe clean one of the single-node clusters and join it to the other to create a two-node cluster that consists of an HA pair.
Let’s see that what will happen during the unplanned event,
- Assume that Node1 and Node 2 own their root and data aggregates.
- If Node1 fails ,
- Node2 takeover root and data aggregates of Node1 .
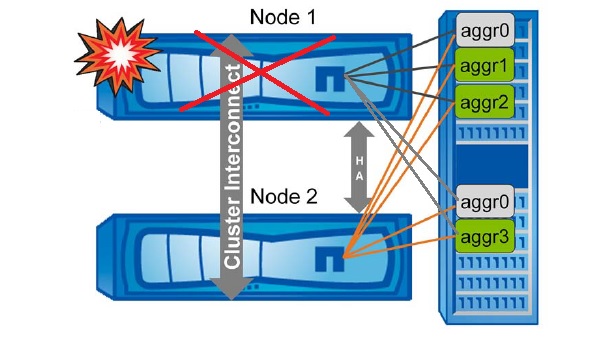
When a node fails, an unplanned event or automatic takeover is initiated (8.2 and prior). Ownership of data aggregates is changed to the HA partner. After the ownership is changed, the partner can read and write to the volumes on the partner’s data aggregates. Ownership of aggr0 disks remain with the failed node, but the partner takes over control of the aggregate which can be mounted from the partner for diagnostic purposes.
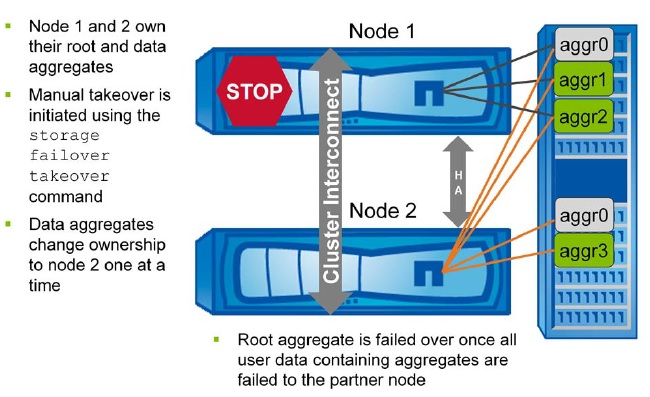
Giveback :
- Automatic or Manual giveback is initiated with storage failover giveback command.
- Aggr0 is given back to node 1 to boot the node.
- Data aggregate giveback occurs one aggregate at a time.
Giveback is initiated by the storage failover giveback command or by automatic giveback if the system is configured for it. The node must have access to its root volume on aggr0 to fully boot. The CFO HA policy ensures that aggr0 is given back immediately to the allow the node to boot. After the node has fully booted, the partner node returns ownership of the data aggregates one at a time until giveback is complete. You can monitor the progress of the giveback with the storage failover show-giveback command. I/O resumes for each aggregate when giveback is complete for that aggregate, thereby reducing the overall outage window of each aggregate.
Aggregation Relocation: (ARL)
Aggregate relocation operations take advantage of the HA configuration to move the ownership of storage aggregates
within the HA pair. Aggregate relocation occurs automatically during manually initiated takeover and giveback operations to reduce downtime during maintenance. Aggregate relocation can be initiated manually for load balancing. Aggregate relocation cannot move ownership of the root aggregate.
within the HA pair. Aggregate relocation occurs automatically during manually initiated takeover and giveback operations to reduce downtime during maintenance. Aggregate relocation can be initiated manually for load balancing. Aggregate relocation cannot move ownership of the root aggregate.
During a manually initiated takeover, before the target controller is taken over, ownership of each aggregate that belongs to the target controller is moved to the partner controller one aggregate at a time. When giveback is initiated, the ownership is automatically moved back to the original node. To suppress aggregate relocation during the takeover, use the -bypass-optimization parameter with the storage failover takeover command.
Planned Event in ONTAP 8.2 with ARL:
When a node takes over its partner, it continues to serve and update data in the partner’s aggregates and volumes. To do this, it takes ownership of the partner’s data aggregates, and the partner’s LIFs migrate according to network interface failover rules.
What is the difference between NetApp CFO and SFO ?
- Root Aggregates are always assigned to CFO (controller Failover) policy.
- Data Aggregates are assigned to SFO (Storage Failover policy)
Check the HA Pair status :
Check the aggregate’s failover policy on the cluster nodes.
Aggr0_xx represents the root volume of controller node.So the failover policy will be set to CFO always. All the data aggregate storage policy has been set to SFO.
Note: We should not store any data volumes on aggr0.
The following commands will help you to identify the failover policy for specific node.
NetUA-01 & NetUA-02 are HA node names.
To disables auto giveback on the HA nodes, use the following command.
To enables the auto giveback on HA nodes, use the following command.
To initiate the failover, use the following command.
You can use either one of the above command to take over the NetUA-02 node’s storage.
Please read the failover man page carefully to know the available option .

No comments:
Post a Comment